이전 까지해서
클라우드 컴퓨팅의 정의에 대해 이야기를 했다.
그렇다면
우리는 더 나아가
왜 클라우드 컴퓨팅으로 패러다임이 변화했는가에
대한 이야기를 시작해볼 수 있을 것이다.
왜 클라우드 컴퓨팅으로 패러다임이 변하였는가?
왜 패러다임이 변화했을까?
클라우드 컴퓨팅이라고 해서
마치 새로운 기술이 나온 것 처럼 느껴지지만
사실 까놓고 이야기 해보면
기술 자체는 새롭고 특별한 것은 아니다.
물론 과거 보다
분산 저장 기술이 발달해
좀 더 효율성 있게 저장하게 되었고,
통신 기술의 발달로 더 빠르게
다운로드 할 수 있고, 업 로드 할 수 있다고 하더라도 말이다.
클라우드 서버의 경우
비슷하게 웹 호스팅 서비스 이용하는 것과 크게 다르지 않다.
왜냐하면 웹 호스팅 서비스를 제공받으면
클라우드 서버를 임대할때와 마찬가지로
서버를 임대 할 수 있기 때문이다.
또한 클라우드 스토리지의 경우도
단순히 저장 공간으로만 활용한다면
기존에 있던 FTP서버와 크게 다를바 없다.
그렇다고 한다면
클라우드 컴퓨팅 자체는
생각보다 우리에게 새로운 기술은 아닐 것이다.
그렇다면
다시 한번 이런 의문이 떠오를 수 밖에 없다.
왜 클라우드 컴퓨팅인가?
이렇게 된다면 다시 원점이다.
그렇지만 일단
기술적으로 특별함 때문은
아닐 것이라고는 생각해볼 수 있다.
이에 대해 몇 가지 이유에 대해 논의해 볼 수 있을것 이다.
① 첫 번째 이유 : 4차 산업혁명에 대한 높은 기대감
아마 가장 큰 이유로서
4차 산업혁명에 대한 사람들의 높은 기대감을
꼽을 수 밖에 없을 것이다.
왜냐하면
지금과 같이 4차 산업혁명에 대한
높은 기대감이 없었다면
클라우드 컴퓨팅을 포함한 4차 산업혁명의 요소들이
지금과 같이 빠르게 발전할수는 없었을 것이다.
이런 높은 기대감을 갖게한 것은
아마 이세돌과 AI 알파고의 바둑 대결이 아닐까 싶다.
이 이후 세계의 많은 언론에서 AI에 대해 이야기하기 시작했고
일반 사람들까지도 AI에 대한 관심을 가지기 시작했다.
그리고 결정적으로
과거 인공지능에 대한 연구가 부진하자
흥미를 잃었던 기업들이 다시 투자를 하기 시작했다.
이를 시작으로 일부에서만 연구하던
머신 러닝에 대한 연구가 유행처럼 퍼지게 되었고
4차 산업 혁명의 시작을 알리게 되었다.
② 두 번째 이유 : 뉴럴 네트워크 기반 AI의
저장 공간을 포함한 리소스 임대
현재 사용되어지고,
연구되어지고,
이야기되어지고 있는 AI는 대개
뉴럴 네트워크(Neural NetWork)기반이다.
뉴럴 네트워크의 강력한 점은
매우 높은 정확성을 가지고 있다는 점인데,
이런 매우 높은 정확성을 가지기 위해서는
수 많은 데이터가 필요하다.
예를 들어
사진이 어떤 꽃인지를
판단 해야 한다고 가정해보자.
만약 사람의 눈이라면,
눈으로 알 수 있는 특징들을 알고 있다면
어떤 꽃인지를
단 한장의 사진으로
단번에 파악할 수 있다.
하지만 뉴럴 네트워크 기반의 AI로
이 사진이 꽃을 나타내는지를 판단하는
수 많은 사진(데이터)를 포함해
이것이 어떤 꽃인지를 판단하기 위해서는
꽃 사진과 꽃이 아닌 사진을 포함해
수 십 만장의 사진(데이터)가 필요하다.
이를 머신 러닝에서 분류(Classification) 라고 하는데
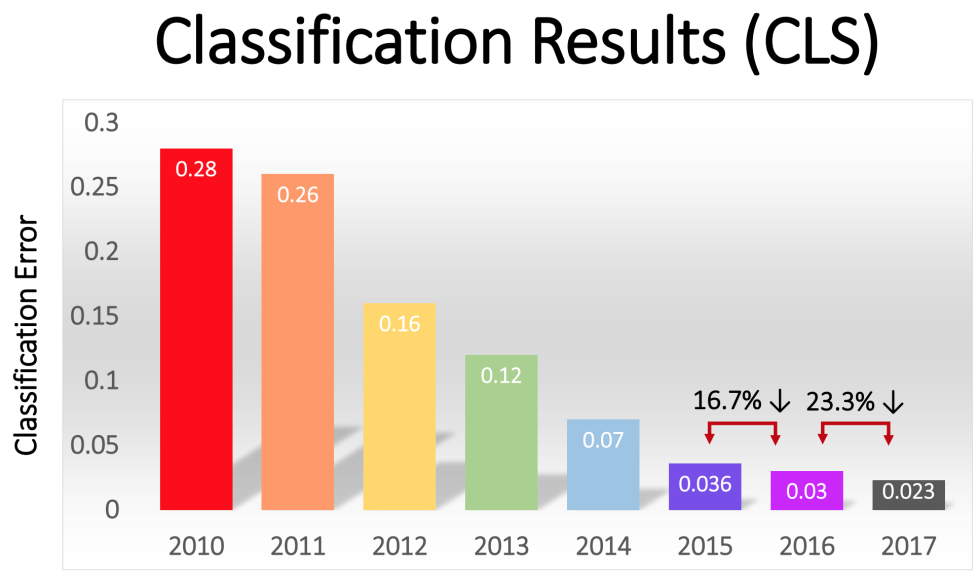
사진을 제공하고 인식률을 겨루는 ILSVRC라는 대회가 있다.
이 대회는 2017년 기준으로 2012년 대회에서 바뀌지 않았지만
무려 15만 장의 사진이 제공되며,
이 사진을 1000개의 객체의 카테고리로 분류하게 된다.
또한 동일한 조건에서 대회를 하기 위해서
1000개의 객체의 카테고리와 120만개의 데이터는
쉽게 이용할 수 있게 대회측에서 패키징해 제공 해준다.
즉, 1000개의 객체를 판별하기 하는 대회를 위해
단순히 계산해서 135만장의 사진을 사용했다는 것이다.
인간이라면 몇 가지 정보만 가지고 있으면
판별이 가능한데에도 불구하고
기계는 수 십 만장의 사진의 데이터가 있어야 한다는 것을 알 수 있다.
위의 사진은 해당 대회의 우승자의 에러율을 나타내는데
2011년과 2012년에 눈에 띄게 에러율이 줄어든 것을 확인 할 수 있다.
이때 사용한 모델은
컨볼루션(Convolution)이라는 선형 연산을 사용하는
컨볼루션 신경망(Convolutional Neural Network, CNN)라고 불리우는
모델을 사용해서 에러율을 비약적으로 낮추었다고 한다.
(일반적인 Nerual Network는 행렬 연산을 한다.)
이 대회를 여는 단체인 ImageNet에서
이미지에 대한 인간의 분류(Classification) 오류율은
5.1%로 보고되었는데
이에 따르면 2015년 부터는
기계가 인간보다 더 낮은 오류율을 가지게 됨으로써
기계가 인간보다 더 나은 분류를 할 수 있다고 볼 수 있게 되었다.
참고로 현재 이 대회는 2017년을 마지막으로
열리지 않고 있기 때문에 2017년이 최신이다.
하긴 이미 인간을 뛰어 넘었는데
해봤자 의미가 없긴 하다.
어쨋든 그렇기 때문에 현재 머신 러닝
특히 딥 러닝이라 불리우는
뉴럴 네트워크 기반의 머신 러닝을 운용하기 위해서는
당연히 이 수 십 만장의 데이터를 저장할 공간과
이를 빠르게 계산하기 위한 컴퓨터가 필요할 것이다.
AI의 붐이 일어났던 과거에는
이런 수 많은 데이터를 저장하고
계산하기 위한 컴퓨터 리소스가 충분치 않았지만
현재에 들어서 하드 웨어가 발전하고
특히 그래픽 카드로 연산을하는 GPU라는
비약적으로 기술의 발달로 인해
CPU 혼자서만 처리해야 했던 연산을
병렬로 처리할 수 있게 됨으로써
같은 리소스를 가진 컴퓨터라도
좀 더 효율이 좋게 계산을 할 수 있게 되었다.
또한 위의 예제에서는
단순히 꽃인지 아닌지를 판단하는 것이지만
우리의 현실에서는
단순히 꽃을 판별하는 것을 넘어서
이것이 집인지, 집의 지붕인지, 아니면 배인지 등의
좀 더 많은 것을 판단하기를 원하기 때문이다.
물론 이 보다 더 중요한것은
클렌징된 데이터겠지만,
클렌징된 데이터가 충분하다면
더 많은 공간과 좀 더 빠른 하드웨어가 필요할 것이다.
그렇다면 이에 대한 솔루션으로
클라우드 컴퓨팅이 될 수 있다.
왜냐하면
많은 데이터를 저장하기 위한 공간은
클라우드 스토리지를,
그리고 이를 계산하고 통신하기 위한 서버는
클라우드 서버를 이용하면 되기 때문이다.
실제 이전에 이야기 했던
AWS에서 제공하는 PaaS에서는
어느 정도 사용되어지고 있는지는 모르겠지만
이미 이러한 것을 지원하고 있고,
사용되어지고 있음에는 틀림이 없다.
③ 세 번째 이유 : 클라우드 컴퓨팅에 대한
사람들의 인식 변화
클라우드 컴퓨팅에
대한 사람들의 인식에 변화도
이러한 패러다임의 변화에 한 몫을 했을 것이다.
사실 클라우드 컴퓨팅에 대해
사람들의 인식은 그다지 좋지는 않았다.
정확히는
남이 관리하는 서버에
자신의 소중한 데이터를 맞긴다는 대한 인식이
좋지 않았다고 하는 것이 옳을 것이다.
물론
서비스를 제공하는 회사측에서는
절대로 보지 않는다고 이야기는 하겠지만
이 세상에 '진리'라는 것
그러니깐 '절대'라는 것은 그리 흔하지는 않으며,
가능성이 있는 이상 의심하는 것은 당연한 것이다.
그러한 인식이 클라우드 컴퓨팅으로 전환을 꺼려하게 했다.
현재들어서 인식이 좋아지면서
다양한 회사에서
클라우드 스토리지 서비스를 제공하지만
사실 먼저 이런 서비스를 시작한 것은 Dropbox였다.
Dropbox는 2007년에 벤처로 시작한 기업이다.
현재 기준 13년 이전에 제시된 솔루션이다.
새로운 것을 거부하는 사람들의 인식이
여지없이 드러내는 현상이라 생각하고 있다.
그렇기 때문에
개인의 입장은 둘째 치더라도,
회사 입장에서는 IDC를 구축해
회사의 데이터들을 모두
IDC에 집어 넣는것이 안전할 것이다.
하지만 이 IDC를 구축하고
운영하는 데에는 많은 비용(Cost)이 든다.
IDC를 구축하기 위한 비싼 하드웨어와
효율성 있는 IDC를 구축하기 위한 비용
그리고 이를 운용하고 유지하고
관리하는 데에 들어가는 비용까지
딱히 계산해보지 않아도
엄청난 비용이 들것은 누구나 알고 있을 것이다.
물론 여기서 말하는 비용이란
물적, 인적 그리고 그 외적인 비용을
모두 포함한 것을 말한다.
그 외적인 비용에는
새벽에 서버 이상이 생길시 출근해야하는
서버 엔지니어들의 고달픔도 들어있을 것이다.
따라서 회사 입장에서는
이런 문제를 해결하기 위한 솔루션이 필요했을 것이다.
그리고 클라우드 컴퓨팅이
이런 고민을 가지고 있는 회사들을 유혹했고,
그들은 비용을 계산한 결과
클라우드 컴퓨팅이 적합하다고 생각한 것이다.
이를 증명하듯이
많은 회사들이 이미
자사 시스템을 클라우드로 전환하였고,
고려하는 회사들도 많이 있다.
그렇다면 개인은 어떨까?
아이폰이 등장으로
스마트폰이라는 패러다임이 생겨났고,
태블릿, 태블릿 PC, 스마트 워치 등의
이를 기반으로한 수 많은 디바이스들이
다양한 회사들에 의해 세상에 나왔다.
이렇게 되면서
개인은 수많은 디바이스를 가지게 되었지만
조금 불편한 것이 생겼다.
각 디바이스의 저장 공간이
따로 존재한다는 점이다.
이러한 점은
다른 디바이스의 데이터를 이용하고 싶을때
개인 사용자로 하여금 불편하게 했다.
예를 들어
컴퓨터를 사용하던 도중에
이전에 스마트폰에서 찍었던 사진이 필요하다고 가정해보자.
이럴 경우 컴퓨터에 스마트폰을 연결해서
사진을 직접 꺼내와야 한다.
하지만 클라우드 컴퓨팅을 이용하여
스마트폰에 저장되어 있는 사진을
클라우드 스토리지에 저장하면
컴퓨터에도, 태블릿에도 그리고
다른 디바이스에서도 공유해서 사용할 수 있다.
어떤 사람들은
별거 아니라고 생각할지는 모르겠지만,
디바이스를 여러개 가지고 있는 사람들에게는 매우 불편하다.
물론 지금에 들어서도
여러 개의 디바이스를 사용하지 않는 사람도 있겠지만
스마트폰, 태블릿, 스마트 워치에 등장으로
주변에서 손쉽게 다수의 디바이스를 사용하는 볼 수 있다.
따라서 일부 데이터를 공유할
저장 공간이 개인에게는 필요해졌다.
그렇기 때문에 클라우드 스토리지라는
클라우드 컴퓨팅의 유혹을
개인 사용자가 뿌리치기는 힘들 것이다.
일정 용량까지는
무료로 이용할 수 있으며
큰 용량이 필요하다면 월 만원으로
인터넷만 있다면 어디서든
어느 디바이스건간에 사용할 수 있는
스토리지를 얻을 수 있게 된다.
나도 작년 부터
MS사의 클라우드 스토리지를 이용하고 있으며,
에세이와 같은 문서들을
클라우드 스토리지에 저장함으로써
생각날 때 마다 스마트폰에서도
그리고 다른 디바이스에서도 작성할 수 있게 되었다.
그 뿐만 아니라 자동적으로
백업도 할 수 있는 효과도 가질 수 있었다.
이를 보면
클라우드 컴퓨팅은 개인에게도
그리고 회사 입장에서도 매우 유용함에는 틀림이 없다.
이러한 유용함이
클라우드 컴퓨팅에 대한
수요를 급 상승 시켰고,
클라우드 컴퓨팅 업체가 작년에 급 성장하게 되었다.
또한 이에 대한 이득을 본 것은
삼성 전자와 SK하이닉스와 같은
파운더리를 주력으로 하는 반도체 회사들이
매출이 급 상승한 것도
클라우드 컴퓨팅에 대한 수요가 증가하자
클라우드 컴퓨팅 서버를 확충하기 위해
대량으로 반도체를 사들였기 때문이다.
④ 네 번째 이유 : 5G의 상용화(예정)
전 세계는 지금 5G 상용화를 앞두고 있다.
5G는 (이론상) 초당 최대 100Gbite로
4G에 보다 약 100배정도 빠르다고 정의되어져 있다.
5G는 크게 중저 주파수(6GHz 이하),
그리고 고 주파수(24GHz 이상)으로 2가지로 나눌 수 있다.
여기까지만 들으면
왜 전부 고 주파수으로 하지 않느냐라는
생각이 떠오른다면 당연하다.
왜냐하면 일반적으로 고 주파수로
가면 갈 수록 속도는 빨라지기 때문이다.
하지만, 전자기파 특성상
주파수가 높으면 높을수록
멀리갈 수 없으며,
벽과 같은 장애물에 취약하기 때문이다.
따라서 24GHz의 주파수는 매우 빠르지만
거리가 멀수록
장애물이 많을 수록 연결이 불안하게 될 수 밖에 없다.
 |
| 위키 백과 영문판 5G : FR2 coverage |
위의 사진을 보면 기지국(base station)과의 거리(distance)가
10미터에서 100미터 정도 밖에 안되는 것을 알 수 있다.
그렇기 때문에 4G와 같은 거리폭을 가지기 위해서는
그 만큼 셀(기지국)이 더 많이 필요하다는 말이다.
물론 한국을 비롯한 많은 나라들의
통신 회사들은 5G를
1년 전 부터 상용화를 했다고는 주장하고 싶겠지만
한국의 경우는 중,저 주파수인 3.5GHz를
5G망으로 이용하고 있기 때문에
그리고 고 주파수를 이용하고 있더라도
기지국(밀리터리파 셀)이 너무 적기 때문에
그것이 정말 5G라고 보기는 힘들다.
5G이기는 하지만
여러가지 면에서 4G와 다를바가 없고
기지국이 너무 적어서 사용할 수 없다면
그런 5G에 무슨 의미가 있을까?
이런 현상은 과거 통신사들이
4G를 상용화를 했을 때와 매우 유사하다.
통신사들 스스로가 4G라 마케팅하여
상용화 시작한 것은 2010년 초반이지만,
표준 4G속도인 1Gbyte/s 에 도달한 것은
LTE Advanced라는 이름의 표준으로
2019년도인 최근이다.
그렇기 때문에
그런 이름 뿐인 서비스를 이용하는 것 보다
4G를 이용하는 것이 지금으로써는 훨씬 유용할 것이다.
그렇다고 하더라도
기술의 문제가 아닌
기지국(밀리터리파 셀)에 수를 늘리는
시간 그리고 자금의 문제일 뿐이다.
그렇다면
28GHz 기지국(밀리터리파 셀)들도
멀지 않은 미래에 설치가 되어질 것이기 때문에
우리들은 조만간 5G를 맛볼 수 있을 것이다.
따라서 5G가 도입된다면
좀 더 좋은 클라우드 컴퓨팅 환경을 가지게 된다.
특히 좀 더 데이터 교환이 필요한
무거운 SaaS도 무리 없이 가동할 수 있을 것이다.
5G는 4G에 비해 (이론상) 높은 속도를 가지는 것도 있지만
SaaS의 경우에는 4G에 비해
지연 시간이 10배정도 낮은것도 한 몫 하기 때문이다.
예를 들면
구글 스태디아가 여기에 해당될 수 있다.
⑤ 다섯 번째 이유 : 플랫폼 화
클라우드 컴퓨팅이 너무나 매력적인 것은
우리들이 사용하고 있는 것들을
모두 한 곳에 모아
플랫폼 화 시킬 수 있다는 것이다.
좀 더 어럽게 말하면
통신하는 프로토콜을 클라우드 플랫폼
단 하나로 맞췄다는 것이다.
과거에는 이러한 인프라들을
각각 구축해야하거나 임대해야만 했지만
클라우드 컴퓨팅에서는
이것들을 한곳에 모아놨기 때문에
그리고 개념화 했기 때문에
더 이상 인프라들을 구하기 위해
이리저리 뛰어다닐 필요가 없게 되었다.
단 하나의 플랫폼만 있다면
우리는 솔루션을 제시할 수 있게 되었다.
결론
과거에는 많은 회사들
그리고 많은 개인들이 데이터 스토리지와 같은
클라우드 컴퓨팅에 대해 의구심을 가지고 있었으나
많은 회사들이 실제로 사용해보니
매우 유용함을 느낌에 따라
클라우드 컴퓨팅 관련 회사가 지난해에 급 성장했다.
특히 MS가 다시 한번
세계 굴지의 IT기업으로 되돌아온것도
클라우드 컴퓨팅 사업 분야에서 성공했기 때문이다.
아마존의 주가 상승 폭을 보면
아마존은 말할 필요도 없을 것이다.
하지만 클라우드 컴퓨팅의
진면목은 아직 드러나지 않았다.
바로 4차 산업 혁명의 핵심이라고 말할 수 있는
머신 러닝 기반 AI는 현재 대부분
뉴럴 네트워크(Neural Network)기반이며,
뉴럴 네트워크에서 최적화된 값을 얻기 위해서는
수 많은 데이터를 저장해야만 하는데
이 저장 공간을 클라우드 컴퓨팅이
활용될 가능성이 가장 크기 때문이다.
또한 (이론상)4G보다 100배 빠르다는
5G도 상용화를 앞두고 있는 시점에서
4차 산업 혁명에서는
이 클라우드 컴퓨팅이 큰 역활을 하게 될 것이다.
따라서
나의 논지에 동의한다면
다음과 같은 결론을 내릴 수 있다.
현재 IT 패러다임이
클라우드 컴퓨팅인 이유는 다음과 같다.
이세돌과 AI 알파고의 바둑 대결로 인해
4차 산업 혁명에 대한 사람들의 기대감을 높인 점,
알파고라고 불리어지는 머신러닝은
뉴럴 네트워크 기반의 AI이기 때문에
수 많은 데이터를 저장할 저장 공간과
이를 계산할 컴퓨터를 포함한 많은 리소스를 필요로 했다는 점,
클라우드 컴퓨팅,
정확히는 데이터 스토리지에 대한 사람들의 인식이 변화하면서
개인은 스마트폰, 컴퓨터, 태블릿 등과 같은 디바이스에서
공통적으로 사용할 수 있는 저장 공간이 필요했다는 것과
회사는 IDC를 운영하는데 있어서
여러가지 어려움을 겪고 있었다는 것이
사람들을 클라우드 컴퓨팅(클라우드 스토리지)으로
이끌게 했다는점
그리고 이를 좀 더 클라우드 컴퓨팅을
원활하게 이용하기 위한
5G가 곧 상용화를 앞두고 있다는 점
그리고 우리들이 사용하고 있는 것들을
클라우드라는 개념으로 한곳에 모아
플랫폼 화 했다는 점을 보면
현재 클라우드 컴퓨팅이라는 개념은
일반 사용자부터 시작해
회사, 그리고 소프트웨어 엔지니어들에게 까지
많은 유용성을 제공해주고 있다.
이런 유용성을 생각해본다면
현재 IT 패러다임은 클라우드 컴퓨팅임에는
누구도 의문을 갖기는 힘들 것이다.
따라서
앞으로 클라우드 컴퓨팅이 얼마나
사람들에 의해 사용되어질지는 모르겠지만
점점 사람들이 클라우드 컴퓨팅에
익숙해지면 질수록
우리들의 시스템은 점점
클라우드 컴퓨팅 위에 올라갈 것이며
어쩌면
가까운 미래에는
지금 처럼 무거운 소프트웨어를 돌리기 위해
좋은 컴퓨터를 구입하기 보다는
클라우드 컴퓨팅 서비스를 이용하게 될지도 모른다.
참고 :
A Study and Comparison of Human and
Deep Learning Recognition Performance Under Visual Distortions -
2020.09.08 내용 다듬기 및 추가