이쪽 공부를 하고 있거나 개발자로서 일을하다 보면
서버 사이드(Server Side)나
클라이언트 사이드(Client Side)라는 말을 들어본 적이 있을 것이다.
특히 개발자가 아니거나 주니어라면
생각보다 제대로된 직감을 가지기는 힘들 것이다.
그런 느낌을 받는다면 당연한 것이다.
처음부터 모든 것을 아는 사람은 없을 것이고,
세상의 모든 것을 아는 사람 또한 없을 것이다.
사실 웹 프로그래밍에서 서버 사이드와
클라이언트 사이드는 엄청난 큰 의미를 가진다.
어느쪽에 중심을 두느냐에 따라
프로젝트의 방향이 다르기 때문이다.
물론 현재에는 클라이언트 사이드 쪽에
중심을 두기는 하지만
5G를 눈앞에 두고 있고,
AI가 발전하고 있는 이 시점에서
그래도 제대로된 직감을 가지고 가야
대비할 수 있지 않겠는가?
평소 같으면 큰 그림을 그리고
작은 그림으로 가는 방식으로 갔었겠지만
좀 더 쉽게 직감에 도달하기 위해
이번에는 조금 다른 방식으로 가보기로 하겠다.
어떤 사람은 평소 이런 의문점을 가지고 있는 사람들이 있을 것이다.
왜 웹 브라우저는 메모리를 많이 차지하지?
라는 생각이다.
내가 이 작업을 하고 있는 시점에
총 6개의 브라우저가 열려있는데
총 메모리는 240.4MB나 사용하고 있다.
단순히 탐색만 했을 뿐인데
이렇게 많은 메모리를 차지한다는 것은 조금 이상하지 않은가?
웹에 대해 잘 모르는 사람들에게는
당연한 의문이다.
이상할 수 밖에 없을 것 이다.
하지만 Web 개발자에게는 어느 정도
이에 대한 직감을 가지고 있을 것이다.
결론부터 말하면
현재 Web쪽에 무거운 처리는 대부분은
클라이언트 사이드 언어로 작업하기 때문이며,
이에 따라 처리 비용이 높기 때문이다.
이에 대한 이야기는 차례대로 설명하기로 하겠다.
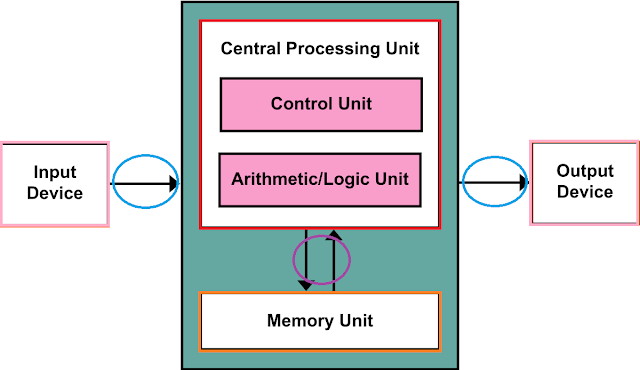
클라이언트 사이드(Client Side)란?
클라이언트 사이드의 정확한 정의는 알 수 없다.
아마 사람들마다 이야기가 조금 다를 것이다.
나는 그 이유에 대해
IT의 기술들은 대부분 필요에 의해 먼저 나오고
그 다음 정의 되어지기 때문이라고 생각하고 있다.
그렇기에 매우 안타깝게도
대부분 그 정의가 제대로 이루어지지 않는다.
어쨋든 나의 직감을 이야기하자면
클라이언트(사용자) 측에서 수행되는 것들 혹은 애플리케이션(언어 등)
으로 이해하고 있다.
조금 다르게 이해하고 있다면 그것으로도 좋다.
우리가 도달하고자 하는 곳은
서버 사이드와 클라이언트 사이드에 대한 이해로
목적이 같기 때문에
다소 직감이 틀리더라도 옳은 방향이라면
큰 문제는 없을 것이다.
IT업계에서는 흔히 있는 일이니 신경 쓰지 않아도 된다.
다시 본론으로 돌아가자면
사실 클라이언트 사이드는 사실 우리 가까이에 있다.
우리는 항상 이런 클라이언트 사이드
애플리케이션을 사용하고 있다.
바로 이런 흔히 말하는 웹 브라우저 말이다.
웹 브라우저는 크게 보자면
클라이언트 사이드(Client Side)의 애플리케이션이라 말할 수 있다.
그리고 좀 더 세부적으로 들어가면
클라이언트 사이드 언어가 언급될 수 있는데
IT업계에서 일하고 있다면
한번 쯤은 들어봤을 법한
JavaScript를 사용하고 있는 추세이다.
또한 가장 최근에 들어서 JavaScript의 여러가지 한계에 의해
Angular.Js나 Vue.js와 같은 JavaScript 프레임 워크가 등장함으로써
이제 웹 업계에서 클라이언트 사이드에서는
사실상 JavaScript와 땔래야 땔 수 없는 관계에 이르렀다.
앞으로는 어떻게 될지는 모르겠지만
IT 웹 업계에 패러다임이 바뀔 정도로
어떤 역사적인 사건이 일어나지 않는 이상
JavaScript는 지속적으로 꾸준히 사용될 것으로 보인다.
어쨋든 클라이언트 사이드 쪽 에서는
웹 페이지(HTML, JavaScript 등이 담긴)를 서버로 부터 받아온 후에
크롬과 같은 클라이언트 사이드 애플리케이션에 의해
클라이언트에서 실행 된다.
정확히는 약속된 형식(프로토콜)으로
코드화 되어 있는 문서를 서버로 부터 받아와
이를 웹 서버 또는 앱 서버에서 해석하고
이에 대한 결과물(웹 페이지)을 클라이언트 사이드에서
사용한다는 것이 더 정확한 설명일지는 모르겠다.
웹 개발자가 자주 사용하게 되는
request 객체나 response 객체는 이러한 약속 중에 하나이다.
좀 더 직감에 도달하기 위해
예를 들어 설명해보자.
당신은 위와 같은
넷플릭스의 메인 웹 페이지에 들어갔다고 가정해보자.
아마 당신은 넷플릭스 회사 서버로부터
이미지부터 시작해 아이콘까지 받았을 것이라 생각하겠지만
전혀 그렇지 않다.
당신이 받은 것은 웹 페이지라는
이상한 언어로 적혀져 있는 코드이다.
이 코드가 궁금하다면
마우스 오른쪽 키를 누르고
페이지 소스 보기를 클릭해보길 바란다.
위와 같은 코드가
빼곡히 적혀져 있는 것만 보일 것이다.
이 코드는 웹 브라우저라는 애플리케이션에 의해
당신의 컴퓨터를 빌려 모든 처리를 하고 화면으로 보여준다.
따라서 당신이 위의 화면을 볼 수 있다는 것은
넷플릭스 서버로 부터 받은 웹페이지의 코드를
당신의 컴퓨터가 모두 처리했다는 것이다.
또한 Email address란에 Email을 적고
Try IT Now라는 버튼을 누르면
보낼때 필요한 작업은
당신의 컴퓨터로 코드를 실행해
결과만 넷플릭스 서버에 전송된다.
다만, 이 과정에서 보안이 취약해질 수 밖에 없는데
결국 서버는 실행해야하는 코드를
클라이언트 사이드에 보내야하기 때문이다.
즉, 공개되면 위험한 코드까지 외부에 노출되며
이를 이용해 악용할 리스크를 높일 수 밖에 없게 된다.
다른 시스템에 비해
수 많은 웹 애플리케이션이 보안에 취약할 수 밖에 없는
근본적인 이유가 바로 여기에 있고 볼 수 있다.
그렇다면 왜 메모리를 많이 차지하는가?
다시 메모리에 대한 이야기로 돌아와 보자.
참고로 지금의 나의 컴퓨터에서 크롬이 530.6MB로
아까보다 메모리를 2배를 더 잡아먹고 있다.
이쯤되면 크롬이 얼마나 메모리를 잡아 먹는지는
이해가 갈 것이라 생각한다.
단순히 크롬이라는 애플리케이션이 무겁기 때문일까?
그렇다면 왜 이렇게 많이 잡아먹는 것일까에 대한
정답은 눈치가 빠른 사람이라면 이미 도달했을 것이라 생각한다.
이유는 바로
서버로 부터 받아온 웹 페이지 안의 코드들이
클라이언트 사이드에서 실행되고 유지되는 비용이
너무 크고 무겁기 때문이다.
무거운 이유는 세 가지 정도 언급될 수 있다.
첫째,
너무 많은 동적 실행 또는 비용이 높은 코드를
클라이언트 사이드에서 부담하고 있다.
둘째,
오랜 시간동안
웹 브라우저를 사용하고 있기 때문에
메모리 누수가 발생했다.
셋째,
최적화 되지 않은
현재 이렇게 무거운 이유는
첫 번째와 두 번째 이유가 가장 크겟지만
세 번째 이유도 어느 정도 비중을 차지하고 있으리라
개인적으로 생각하고 있다.
왜냐하면
최근 급속도로 하드웨어의 비약적인 발전으로
엄격하게 최적화를 할 필요성이 사라졌기 때문이다.
특히 최근 많이 사용되어져 있는 기술인 동적 웹페이지 기술,
예를 들어
위와 같이 네이버에서 사용자가 타이핑 칠 때 마다
보이는 자동 검색 결과 달라지는 것과 같은 기능
즉, 한 페이지에서 계속해서 바뀌어지는
이러한 기술들은 더더욱 메모리를 차지 한다.
따라서 이런 사용자들에게 새로운 경험을 주는
동적 기술들을 많이 사용한 페이지일 수록
메모리는 더더욱 차지하게 될 것이고
크롬이라는 클라이언트 사이드 애플리케이션은
메모리를 더 할당 할 수 밖에 없다.
이렇게 된 근본적인 이유는 서버에서
웹페이지만 받아오던 이런 개념에서
동적이라는 것을 표현해야하기 때문에 나타난다고 생각하고 있다.
인터넷이
즉, 웹 페이지가 움직이는 메커니즘은
기본적으로 웹 서버라는 미들웨어와
정적인 페이지를 교환하기 때문에
페이지 자체를 동적으로 바꿀 수 없다.
그렇기에 이를 기술적으로 우회해
마치 움직인 것 처럼 꾸민 것 뿐이다.
이 과정 속에서 정적인 웹 페이지를 만을 생성하던
웹 서버는 동적인 처리를 하기 위해 앱 서버가 되었다.
물론 그렇다고 하더라도
하드웨어가 충분하기 때문에
최적화가 필요 없다는 말을 개발자가 하는 것은 옳지 않다.
하지만, 다른 IT업계보다
웹 업계는 더욱 솔루션에 집중해야 하기 때문에
최적화는 우선 순위에서 멀어진 것 뿐이다.
어쨋든 이쯤 되면 크롬과 같은
클라이언트 사이드 애플리케이션을
사용하는 사용자 입장에서는 조금 억울할 것이다.
왜냐하면
자신의 컴퓨터의 리소스를 사용하는 것이므로
조금 손해보는것 같은 느낌이 들 것이기 때문이다.
(자신의 하드웨어 리소스가 충분하더라도)
하지만,
모든 행동에는 어쩔수 없는 이유가 있듯이
이 또한 그럴 수 밖에 없는
서버 측의 고충이 있기 때문이다.
그 이야기에 대해서는
다음 장 서버 사이드에 대해 이야기를 할 때
이어서 설명하기로 하겠다.
나의 설명이 클라이언트 사이드에 대한
직감을 캐치하는데 도움이 되었길 바란다.
왜 브라우저 마다 메모리 점유율이 다른가?
DOM이라고 들어본적 있는가?
DOM은 Document Object Mode의 약자로
클라이언트 사이드에서 사용하는 API를 말한다.
이 DOM은 각 클라이언트 사이드 애플리케이션인
크롬, 파이어 폭스와 같은 웹 브라우저에 내장되어 있다.
물론 JavaScript 또한 내장되어 있다.
W3C DOM라는 곳에서 표준을 제안하지만
강제성은 없기 때문에
각 브라우저 개발사마다
자사에서 개발한 고유의 API를 사용하기도 한다.
따라서
Chorme, Edge, FireFox 등에서 사용하는 DOM은
일부 같을 수 있으나, 다를 수도 있으며
해당 함수의 이름이 조금 다름으로 인해
실행할 수 없는 경우도 발생할 수 있다.
그렇기에
같은 기능을 가지는 API라고 하더라도
최적화가 잘되어 있는
API를 가지고 있는 웹 브라우저라면
해당 기능에 한 해서는
메모리 점유율이 다소 낮을 수는 있다.
히지만 그렇다하더라도
엄청난 큰 차이는 나지 않을 것이다.
가끔 브라우저를 통해 어떤 사이트에 접속했을때
아래와 같은 화면을 본 적이 있을 것이다.
위와 같은 경우는
Explorer 11과 Chrome에 최적화 되어있는 사이트이다.
그렇다면 이제는
왜 이러한 사이트들이 최근에는 보기 힘들지만
과거에는 존재하는지 이해할 수 있을 것이다.
각 브라우저 마다 안에 내장되어 있는
클라이언트 사이드의 웹 API가 동일한 API도 있지만
그렇지 않은 API도 있기 때문이다.
이에 따라
위 사진 상의 웹 시스템의 상황을
크게 두 가지 추측해 볼 수 있을 것이다.
첫째,
Explorer 11 이상의 DOM에서만
지원하는 기능을 사용하고 있으며,
크로스 브라우징을 Chorme만 완료하였다.
두 번째,
Explorer 11이상의 DOM에서만
지원하는 기능을 사용하고 있으며,
사용한 DOM의 일부 API와
Chorme의 DOM 호환이 가능 혹은 동일하다.
만약 이외에 브라우저를 사용하게 된다면
일부 기능은 정상적으로 작동하겠지만
Explorer 11과 Chorme의 DOM에서만
제공하는 기능이 작동하지 않을 것이다.
즉,
각 브라우저에서 사용되고 있는
DOM과 최적화 정도의 차이가 있기 때문에
크롬, 파이어 폭스와 같은 웹 브라우저들이
같은 사이트를 들어가더라도 점유하는 메모리가 다를 수 있는 것이다.
이어서 서버 사이드에 관해 관심있다면
아래의 링크의 페이지를 참고해보길 바란다.