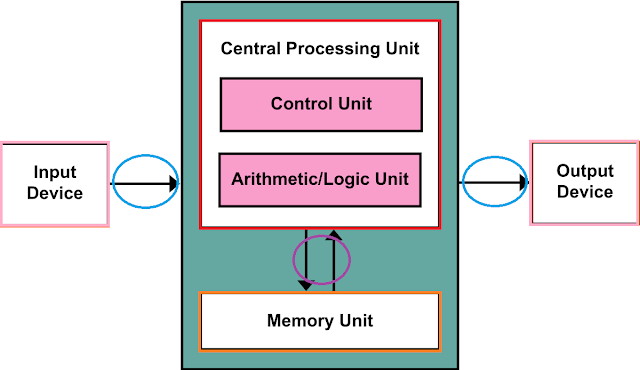
앞선 글에서 나는 뉴런 네트워크를 설계하고,
프로세스를 정했다.
하지만, 곧 문제에 직면했는데,
내가 코세라에서 배운 이론들은 꽤 예전에 이론들이며
시간이 된다면 완수하고 싶지만
나는 그 강의를 아직 완수하지 않았기 때문에
현재 Python에서 사용하고 있는 라이브러리 들은
내가 알던 것들과는 조금 다른 용어들을 사용하고 있었으며,
그에 따른 수식들 또한 달랐다.
물론 이에 대해 다시 강의로 되돌아가
이에 대해 배우는 것이 어쩌면 빠를 수 도 있지만,
나는 먼저 강의를 다 듣는 것 보다는
하나의 토이 프로젝트를 해보는 것이 더 이득이라 판단 했다.
왜냐하면
나는 기본을 바닥에 올려놔야할 때는
바텀 업을 선호하지만,
어느 정도 기본이 쌓였다면
탑 다운 방식을 선호하기 때문이다.
따라서 프로젝트를 진행하기 앞서서
내가 배웠던 것들과 실제 라이브러리에서 사용하는
수식들이 어떻게 다른지
그러니깐 어떻게 발전했는지에 대한 비교가 필요하다고 판단했다.
이에 대한 첫 장으로 먼저
Cost Function과 Active Function에 대한 이야기를 해보려한다.
Active Function? Cost Function? Loss Fuction?
NN관련에 대해 검색하다보면
익히 나타나는 용어는 Cost Function, Active Function,
Loss Function이 3가지 용어가 자주 보이는 듯 하다.
여기서 Cost Function에 대해서는 학습을 했었고,
과거 포스팅에도 개재한 바 있다.
과거 포스팅에서 Cost Function에 대해
내가 정의 내린 것은 아래와 같다.
데이터들의 집합인 가설 함수(Hypothesis Function)와
즉, 최소값인 θ0, θ1를 구하는 것이 비용 함수(Cost Function)이다.
수 많은 데이터들을 분류할 기준이 필요하게 되는데,
그 기준에 해당하는 선을 구해야 하기 때문이다.
훈련 예제로 들어가는 데이터들이 많을 수 밖에 없다.
이 근접한 값이 비용 함수(Cost Function) θ0, θ1이다.
즉, 수 많은 데이터들을 분류하기 위해
이 경계를 나누는 선이 필요하며,
수 많은 데이터들을 고려했을 때의 최적의 선의 θ0, θ1값이
바로 비용 함수(Cost Function)라는 것이다.
그렇다면 나머지 Active Function과 Loss Function은 무엇일까?
우선 손실 함수(Loss Function)의 경우는
비용 함수(Cost Function)와 매우 유사하며
정의 또한 엄격하지 않다고 한다.
역시 IT 용어 답다.
또한 이에 대해
Ian Goodfellow, Yoshua Bengio, Aaron Courville의
"Deep Learning" 책 섹션 4.3에 따르면
이에 대해 아래와 같이 이야기 한다.
The function we want to minimize or maximize is called the objective function, or criterion.
우리는 최소화 하거나 최대화하는 함수를 목적 함수 또는 기준 함수라고 부른다.
When we are minimizing it, we may also call it the cost function, loss function, or error function.
최소화 할때 우리는 비용 함수, 손실 함수, 또는 오류 함수라고 부르기도 한다.
In this book, we use these terms interchangeably,
though some machine learning publications assign special meaning to some of these terms.
이 책에서는 이러한 용어들을 바꾸어 가면서 사용하지만,
일부 기계 학습 책에서는 이러한 용어 중 일부에 특별한 의미를 부여하기도 한다.
또한 참고한 출처 사이트 중
가장 많은 추천 수를 받은 답글에서는 아래와 같이 정리하였다.
A loss function is a part of a cost function
which is a type of an objective function.
손실 함수는 목적 함수의 포함되는 비용 함수의 일부 중 하나이다.
All that being said, thse terms are far from strict,
and depending on context, research group, background,
can shift and be used in a different meaning.
문맥, 연구 구룹, 목적에 따라 다른 의미로 사용될 수 있다.
With the main (only?) common thing
being "loss" and "cost" functions being something
that want wants to minimise,
and objective function being something one wants to optimise
(which can be both maximisation or minimisation).
즉, 비용 함수(Cost Function)과 손실 함수(Loss Function) 그리고
목적 함수(Objective Function)의 의미는 사실상 같고
어떤 관점에서 바라보느냐
즉, 어떤 학문에서 바라보느냐의 따라 다를 수 있다고
나는 직감을 가지고 있다.
또한 직관적으로 따진다면,
손실 함수 쪽이 더욱 직관적일 수 있으나,
일반적으로 사용되는 용어가
비용 함수이기 때문에
커뮤니케이션 관점에서
나는 비용 함수를 사용하는 쪽이 더 좋다고 본다.
그렇다면
이제 Active Function에 대한 이야기로 넘어가자.
Active Function에 대한 정의
활성화 함수(Active Function)의 경우
비용 함수와 손실 함수와는 궤를 달리하는데,
활성화 함수는
연결된 노드로 신호 전파를 제어하기 위해
즉, 해당 노드를 활성화할 것인지에 대해 결정하기 위해
각 노드에 적용되는 함수이다.
대표적인 예가 시그모이드 함수이다.
활성화 함수가 필요한 이유는 간단하다.
뉴런 네트워크는 실제 인간의 뉴런에 착안한 이론이고,
실제로 인간이 정보를 받아들이려고 할 때,
'중요한 정보'와 '덜 중요한 정보'를 판단해야 하기 때문이다.
동일하게 뉴런 네트워크도
이와 유사한 메커니즘이 필요했고,
이에 대한 솔루션이 바로 '활성화 함수'라는 것이다.
이전에 포스팅에서 이야기 했듯이
뉴런 네트워크는
Input layer 부터 데이터를 받아
Hidden layer에 있는 가중치(Weight)를 곱하고 편향(Bias)을 더함으로써
Hidden layer의 하나의 노드 값이 정해지는데,
활성화 함수는 이 하나의 노드 값이 정해지면 실행 된다.
이 과정이 반복되고 최종적으로 Output Layer까지 도달하면
뉴런 네트워크를 통해
우리가 얻고자하는 해답을 얻을 수 있다.
Input layer 부터 Input layer까지 도달하는 것을
순방향 전파(Forward Propagation)라고 한다.
하지만, 만약 도출된 Output이 실제 값(학습된 값)과 거리가 멀다면
이 Output을 활용해 오류가 계산되고,
이 오류값을 기반으로 뉴런의 가중치와 편향이 업데이트 된다.
이를 역전파(Back Propagation)라고 한다.
즉, 훈련 데이터 수 만큼
이 순방향 전파와 역전파가 이루어 지고,
뉴런 네트워크를 통해 우리가 원하는 값을 얻을 수 있으며,
이 것이 뉴런 네트워크의 핵심이다.
라는 것 까지가 내가 배운 것이다.
나는 배울 당시 시그모이드 함수라는 것을 하나 배웠었는데,
이 시그모이드 함수가 활성화 함수 중 하나이다.
여기서 이런 의문이 들 수도 있다.
이 활성화 함수라는 것이 꼭 필요할까라는 것에 대해서 이다.
왜냐하면
안 그래도 많은 데이터들을 필요로하는 뉴런 네트워크에서
이런 활성화 함수까지 넣으면 비용이 더욱 증가하는 것은
너무나도 자명하기 때문이다.
하지만, 내가 이 글을 작성할때
활성화 함수를 사용하지 않는 뉴런 네트워크는
신뢰성이 떨어지고, 복잡한 패턴을 학습할 수 없다고 하며
활성화 함수를 사용하지 않는 모델은
선형 회귀 모델(Linear Regression Model) 뿐이라고 한다.
그렇다는 것은
결국 엔터프라이즈 시스템에서 활용할만한
머신 러닝은 이 활성화 함수를 사용하는 것이
필수불가결하다는 결론을 내릴 수 있다.
(엔터프라이즈 시스템에서는 유연성이 필요하기 때문)
그렇기에 일단 이러한 의문은 접어 두기로 하자.
나는 솔루션을 제시하는 엔지니어이지
연구하는 연구자가 아니다.
연구는 훌륭하신 석사/박사 분들의 몫으로 돌리겠다.
그렇다면,
이번 기회에 시그모이드 외에도
몇 가지 추려서 시야를 조금 더 넓혀보자.
현재 시점에서 많이 사용 되는 활성화 함수에 대해 이야기 해보자.
여기서 이야기할 활성화 함수는
시그모이드와 유사한 tanh 함수와 ReLU 계열, softmax 그리고
구글 팀에서 개발했다고 하는
Swish에 대해 이야기 해보려 한다.
활성화 함수 : tanh
위의 그림은 시그모이드와 tanh 함수의 그래프를 보여준다.
시그모이드와 tanh 함수의 차이는
원점을 중심으로 대칭을 이룬다는 점이다.
따라서 기본적인 수식은 시그모이드와 매우 유사하다.
tanh(x)=2sigmoid(2x)-1
그리고 위의 수식을 풀어보면
tanh(x) = 2/(1+e^(-2x)) -1
위와 같은 수식으로 표현이 가능하다.
위에 그래프에서 나타나듯이
시그모이드 함수는 0과 1사이의 값으로 압축되기 때문에
즉, 음수 값 까지 0이나 0에 가까운 값으로 압축(매핑)되기 때문에
역전파를 진행하는 과정에서 가중치는 유효하게 업데이트 되지 않으며
신경망이 마치 멈춘것과 같은 것 처럼 보이게 된다.
즉,
기울기 소실 문제(Vanishing Gradient Problem)라고 불리는
현상이 나타난다는 단점이 있는데,
-1과 1사이의 값으로 압축해주는 tanh 함수는
이 기울기 소실 문제를 해결해 줄 수 있으며,
좀 더 크게 분포해 있기 때문에 시그모이드 보다
강력한 도함수임을 나타내 준다.
따라서 일반적으로는 활성화 함수로
시그모이드 함수를 사용하는것 보다 tanh 함수를 사용하는 것이
더 좋은 선택일 수 있다.
다만, 간단한 뉴런 네트워크 아키텍처라던가
이진 분류 문제에 있어서는
시그모이드 함수가 여전히 더 좋은 선택일 수도 있다.
그렇기에 내가 진행하고 있는
Toy Project는 시그모이드가 가장 적절하다고 이야기할 수 있다.
활성화 함수 : ReUL 계열
ReUL 계열의 함수는 현재
대부분의 뉴런 네트워크 아키텍쳐에서 사용하고 있다고
말할 수 있을 정도로 자주 사용되고 있는 활성화 함수이다.
왜냐하면, 시각적인 이미지 분석에 특화되어 있는
그리고 딥러닝이라고 불리기도 하는 CNN
(Convolutional Neural Network, 컨볼루션 신경망)에서
사용되어지는 활성화 함수이기 때문이다.
ReLU는 Rectified Linear Unit의 약자로
다른 활성화 함수 대신 ReLU를 사용함으로써 얻을 수 있는 이점은
모든 뉴런을 동시에 활성화 하지 않는다는 점이다.
따라서 기본적으로 ReLU 계열은 sigmoid 와 tanh의 비해
최대값를 계산하는 것이 매우 빠르다고 할 수 있기 때문에
뉴런 네트워크 전체적인 비용이 절감된다고 할 수 있다.
ReLU는 여러가지 함수가 존재하지만,
여기서는 두 종류 기본적인 ReLU와 Leakly ReLU를 소개하려고 한다.
오른쪽은 Leakly ReLU의 그래프를 나타난다.
위에서 잠깐 언급했듯이
ReLU 계열들은 모든 뉴런을 동시에 활성화하지 않기 때문에
뉴런 네트워크의 비용을 절감시킬 수 있다.
하지만, 시그모이드 함수에서 나타났던 문제와 유사하게
모든 음수를 0으로 처리해버리기 때문에
시그모이드 함수와 동일하게 역전파 과정에 영향을 미쳐
신경망이 멈춘것과 같은 문제를 일으킨다.
그렇기 때문에 이 문제를 해결하기 위해서
파생되어 나온 것이 Leaky ReLU이다.
먼저 ReLU를 살펴보면 입력 값이 음수 일 경우
즉, 비활성화 되었을 때는 0의 상태가 되며,
음수가 아닐 경우 선형적으로 나타난다.
ReLU의 수식은 아래와 같이 나타낸다.
f(x)=max(0,x)
다음으로 Leaky ReLU에 대해 살펴보자.
Leaky ReLU에서는 음수의 값이 나타나지 않는다는
ReLU에서의 문제를 해결 했다.
Leaky ReLU의 수식은 아래와 같다
이외에도 여러가지 변형된 ReLU가 있어보이지만
이 두 가지만 알고 넘어간다면
토이 프로젝트를 진행하는데에 있어서
큰 문제는 없어 보이기에 2 가지만 이야기 하기로 하겠다.
활성화 함수 : Softmax
소프트 맥스(Softmax)는
다중 시그모이드(또는 다항 로지스틱 회귀)라고 이야기 한다고 하는데
그 이유는 다중 클래스에 대한 활성화를 판단해주지만
0과 1사이의 값을 반환해주기 때문이며,
소프트 맥스에서 출력하는 값의 합은 1이라는
0.08, 0.11, 0.81
위의 값은 3개의 클래스에 대한 값인데,
이 3개의 값의 합은 정확히 1이되기 때문에
이는 이진 분류에서만 사용하는
시그모이드와 다르게
다중 클래스에 대해 대응이 된다는 이야기이며
또한 각 클래스의 값은 1이 넘지 않기 때문에
확률 분포를 따르는 입력 값을 정규화 하기 때문이다.
다만, 다중 클래스의 경우
2차원 그래프로 표현할 수 없기 때문에
다른 활성화 함수와 다르게
수식만 보고 넘어가기로 하자.
소프트 맥스의 수식을 위와 같으며,
위의 그림은
활성화 함수로 소프트 맥스를 선택할 경우의
Input와 Output을 보여준다.
활성화 함수를 소프트 맥스로 선택할 경우의 과정을 보여주는데,
각 input에 따른 정규화 값들이 input으로 나오는 것을 확인 할 수 있다.
활성화 함수 : Swish
마지막으로 Swish에 대해 이야기 해보자.
Swish는 Google의 연구원에 의해 개발된 활성화 함수로
ReLU 계열 만큼 효율 적이며, 심층 모델(딥 러닝)에 있어서
보다 나은 성능을 보여준다고 한다.
위의 수식은 Swish 함수의 수식을 보여주며
모든 음수 값에 대해 대응함(미분 가능)은 물론이고
ReLU 계열의 그래프들 보다 부드러운 곡선을 지니고 있다.
이는 뉴런 네트워크를 최적화함에 있어서 중요한 역할을 한다고 한다.
Swish 함수의 재미있는 점은
시그모이드를 활용하고 있음에도
즉,
위에서 언급한 시그모이드를
활용하는 활성화 함수들이 늘 그렇듯이
기울기 소실 문제(Vanishing Gradient Problem)가
나타나는 점을 안고 있을 수 밖에 없는데
ReLU 계열의 활성화 함수와 유사한 성능을 가지고 있다는 점이다.
ReLU와 Swish 함수를 비교하면서 아래와 같이 설명한다.
With MNIST data set, when Swish and ReLU are compared,
MNIST 훈련 데이터 셋을 사용하여 Swish와 ReLU를 비교해봤을 때
both activation functions achieve similar performances up to 40 layers.
두 활성화 함수는 최대 40 레이어 까지 유사한 퍼포먼스를 가진다.
However, Swish outperforms ReLU by a large margin
in the range between 40 and 50 layers
when optimization becomes difficult.
하지만, Swish는 최적화가 어려워지는 40~50개의 레이어 범위에서
Swish 쪽은 비교적 최근에 언급되어지고 있기 때문에
앞으로 많은 발전을 기대해봐도 좋을 것 같다.
결론
그렇다면 어떤 활성화 함수가 적절할까?
결론적으로 어떤 활성화 함수가 좋을까에 대해
경우에 따라 어떤 활성화 함수가 좋을 것이다 라는 이야기만 있었을 뿐이였다.
학자들이나 전문가들 사이에서도
구체적으로 표준이 아직 정해지지 않은 듯 하다.
아직 연구 단계이니 어찌보면 당연하다고 볼 수 있다.
다만, 한 가지 알 수 있었던 것은
기본적으로 ReLU 함수를 사용하며,
뉴런 네트워크가 최적화 되지 않을 경우
다른 함수를 사용하는 것이 좋다는 것이다.
아마 이에 대한 대안으로
Swish를 사용해보는 것이 좋지 않을까 싶다.
2020.08.28 Swish 내용 개선 완료, 결론 추가