손실 함수의 구현으로 활성화 함수 계산을 추가한
예측 값이 얼마 만큼의 오류를 가지고 있는 지에 대한 평균 값을 얻을 수 있었다.
그 다음은 역전파를 구현할 차례이다.
이번 포스팅의 코드들은 모듈화 되지 않은
날것에 가까운 코드 이기 때문에 정렬되어 있지 않다.
이 포스팅 다음에 모듈화를 진행할 예정이다.
역전파에 대해
앞서 이야기 했듯이
손실을 구했다면, 당연히 예측 값을 조절해
최대한 손실이 없게 끔 만들어야 한다.
어떻게 해야될까?
가장 일반적인 방법은 가중치를 미세하게 조절하면서
손실 함수가 최소화 될 때 까지 반복하는 것이다.
즉, 상수 값인 기울기(가중치)를 조절하는 것이다.
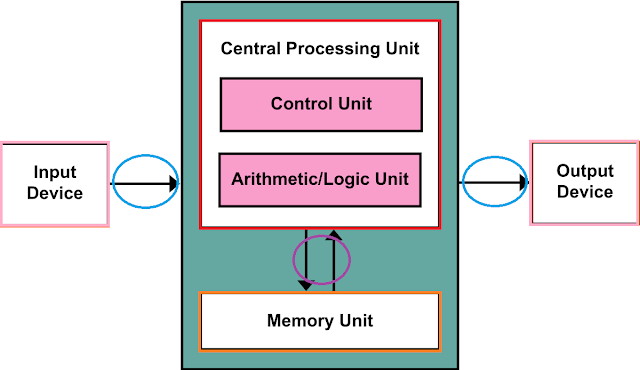
역전파 프로세스는
활성화 함수에서의 역전파(backward) 단계에서는
순방향 전파에서 계산한 값을 가지고
가중치와 편향을 미세 조절 하기 위한 가중치(gradient)를 결정 한다.
레이어의 역전파(backward) 단계에서
이 가중치를 레이어에서 넘겨 받아
이 값을 가지고 레이어가 가지고 있는 가중치와 편향을 업데이트 한다.
역전파는 말 그대로 역으로 값을 전달하며
진행되기 때문에 연쇄 법칙(Chain Rule)이라고도 한다.
다만 이전 과정에서 구현했던 활성화 함수, 손실 함수를 포함해
레이어의 역전파를 구현해야 하기 때문에
수식에 대한 더 많은 이해와
이전 보다 더 많은 코드 추가가 필요할 것 이다.
그렇기에 구현 하는데 있어서 예상보다 시간이 소모되었기에
역전파의 구현은 활성화 함수는 ReLu, Softmax를
그리고 손실 함수는 범주형 교차 엔트로피(Categorical Cross Entropy,CCE)만을
포스팅 할 예정이다.
차후에 이진 교차 엔트로피와 다른 활성화 함수에 대한
역전파 구현은 차후에 수학적인 내용에 들어갈때 같이 구현하기로 하겠다.
그렇다면 역전파라는 말대로, 반대로 타고 들어가보자.
역전파의 구현 : 출력 레이어
이전에 언급한대로 활성화 함수로
소프트 맥스와 ReUL를 선택했기 때문에
이에 따라 범주형 교차 엔트로피를 구현해야 한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | class Loss_CategoricalCrossentropy(Loss_CCE): def CCE_forward(self, y_pred, y_true): #오버플로우 방지를 위해 값을 조정 y_pred_clipped = np.clip(y_pred, 1e-7, 1-1e-7) loss_cce = -np.sum(y_true*np.log(y_pred_clipped)) return loss_cce def CCE_backward(self,y_pred, y_true): n = y_true.shape[0] # 실제 확률 분포가 one-HotEncoding화 되어있지 않을때 if len(y_true.shape) == 1: gradient = y_pred gradient[range(n),y_true] -= 1 gradient = gradient/n #실제 확률 분포가 one-HotEncoding화 되어있을때 elif len(y_true.shape) == 2: gradient = (y_pred-y_true)/n return gradient | cs |
범주형 교차 엔트로피의 경우 각 요소의 합이 1이기 때문에 간단하다.
예측된 확률 분포와 실제 확률 분포의 차이 값에 전체 갯수를 나누어주면 된다.
계산되어 기울기(gradient)에 저장된 값은 SoftMax에 전달된다.
shape 매소드를 활용해 실제 확률 분포 변수인 y_true가
one-HotEncdoing화가 되어 있는지를 판단하게 하였다.
정상적인 y_true 값이라면, 모두 동일한 값이 산출 된다.
① 소프트 맥스
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | class Activation_Softmax(Layer): def __init__(self, output_cnt): self.units = output_cnt self.type = 'Softmax' def forward(self,inputs): #오버플로우를 방지하기 위해 최대값을 빼줌 exp_values = np.exp(inputs - np.max(inputs, axis=1, keepdims=True)) probabilities = exp_values / np.sum(exp_values, axis=1, keepdims=True) self.output = probabilities return self.output def backward(self,gradient): forward_soft = self.output self.output_back = forward_soft * (gradient -( gradient * forward_soft).sum(axis=1, keepdims=True)) return self.output_back | cs |
위에서 잠깐 언급한대로 레이어에 전달할 기울기를 산출 한다.
이 뉴럴 네트워크 코드에서
소프트 맥스의 역전파(backward) 단계에서 매개변수로 받는 기울기는
범주형 교차 엔트로피의 역전파에서 산출된 값이다.
② ReUL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | class Activation_ReLU(Layer): def __init__(self, output_cnt): self.units = output_cnt self.type = 'ReLU' def forward(self,inputs): self.output = np.maximum(0, inputs) return self.output def backward(self,gradient): foward_ReLU = self.output self.output_back = gradient * np.where(foward_ReLU<=0, 0, 1) #self.output_back = gradient * np.heaviside(foward_ReLU,0) return self.output_back | cs |
np.where 함수는 ReLU 순방향 전파로 얻은 각 요소가
0보다 작거나 같을 경우 0으로 값을 바꾸며,
0보다 클 경우 1로 바꾸는 작업을 한다.
밑에 주석 처리한 코드와 정확히 동일한 작업을 한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | class Layer: def __init__(self): pass def forward(self): pass def backward(self): pass class Layer_Dense(Layer): def __init__(self, n_inputs, n_neurons): #randn : 0으로 중심으로한 가우스 분포를 무작위 생성 #실제 randn 함수는 1을 초과한 값을 출력하기 때문에 0.10을 곱함 self.weights = 0.10 * np.random.randn(n_inputs, n_neurons) #뉴런 수만 큼 무작위로 편향(값) 생성 self.biases = np.random.rand(1,n_neurons) def forward(self, inputs): self.input = inputs #순방향 전파 수식을 표현 self.output = np.dot(inputs, self.weights) + self.biases return self.output def backward(self, d_activation): learning_rate = 0.15 #delta d_input = np.dot(d_activation,self.weights.T) #가중치 오류률 산출 d_weight = np.dot(self.input.T,d_activation) #편향 오류률 산출 d_bias = d_activation.mean(axis=0,keepdims=True) #가중치, 편향 업데이트 self.weights -= learning_rate * d_weight self.biases -= learning_rate * d_bias return d_input | cs |
후에 모듈화 작업을 하기 위해
먼저 Layer라는 인터페이스를 만들었다.
레이어의 역전파(backward)는 활성화 함수 기울기 값을 이용해
가중치, 편향의 오류률을 산출하고
오류률을 사용해 업데이트 할 상수를 계산해
레이어가 가지고 있는 가중치와 편향을 업데이트 한다.
변수 learning_rate는 모듈화 할때 매개 변수로 사용할 것이다.
테스트 : 학습
학습의 전체적인 코드는 아래와 같다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | #X, y = spiral_data(samples=100, classes=3) X, y = vertical_data(samples=100, classes=3) NN_tools = NN_tools() y_true = NN_tools.oneHotEncoding(y) dense1 = Layer_Dense(2,4) activation1 = Activation_ReLU(4) dense2 = Layer_Dense(4,3) activation2 = Activation_Softmax(3) loss_function = Loss_CategoricalCrossentropy() for iteration in range(100): #순방향 전파 프로세스 dense1.forward(X) activation1.forward(dense1.output) dense2.forward(activation1.output) activation2.forward(dense2.output) #손실 계산 loss = loss_function.forward(activation2.output, y_true) print("Loss:", loss) #손실의 기울기 계산 back_CCE = loss_function.backward(activation2.output, y_true) #역전파 프로세스(산출된 손실 기울기를 기반으로 반복) for iteration_back in range(100): act2_back = activation2.backward(back_CCE) dense2_back = dense2.backward(act2_back) act1_back = activation1.backward(dense2_back) dense1_back = dense1.backward(act1_back) #역전파로 조정된 가중치, 편향으로 다시 한번 순전파 프로세스를 실행 dense1.forward(X) activation1.forward(dense1.output) dense2.forward(activation1.output) activation2.forward(dense2.output) loss = loss_function.forward(activation2.output, y_true) print("predict Loss:", loss) | cs |
이제 수직, 나선 분포의 데이터를 가지고 결과값을 살펴보자.
데이터의 분포는 보통 2가지로 예상해볼 수 있을 것이다.
수직(vertical)형과 나선(Spiral)형이다.
사용하고 있는 훈련 데이터의 수직형은 아래와 같은 분포로 데이터가 위치해 있다.
한눈에 봐도 같이 색이 되도록 주변에 분포되어 있기 때문에 분류하기 매우 편해보인다.
최적화가 최대한 이루어진 경계선이 정확히는 알 수 없으나
대략적으로 추측이 가능하기 때문이다.
아마 최적화된 경계선은 위와 같은 선이 될 가능성이 크다.
이 데이터를 가지고 훈련을 해보면 아래와 같은 결과가 나온다.
 |
| 훈련 시작 부분 |
위의 사진으로 보면 약 손실 값이 1.1에서 눈에 띌 정도로
줄어드는 것을 확인할 수 있다.
이를 통해 구현이 제대로 이루어 진것을 알 수 있다.
 |
| 훈련 끝 부분 |
끝 부분에서 오류률이 0.44까지 내려가며
다시 순전파를 진행할 때 0.46의 값이 나옴으로써
역전파를 통해 레이어의 가중치와 편향이 이전보다 오류률이 줄은 것을 알수 있다.
다만, 값을 보면 값이 증가했다가 줄어들었다하는 패턴을 보이는 것을
볼 수 있는데, 이는 학습 비율(변수 learning_rate)이 크기 때문이다.
이 값을 적절하게 조절하면 안정적이게
손실 값이 줄어드는 것을 확인할 수 있을 것이다.
나선 분포는 아래와 같이 데이터가 위치해 있다.
분류에 따른 데이터가 산발적으로 분포되어 있기 때문에
적절한 경계를 정하기가 어려워 보인다.
결과 값을 살펴보자.
 |
| 훈련 시작 부분 |
오류값이 1.1부터 시작해 수직 분포의 경우보다
오류률이 눈에 띄게 줄어들지 않는 것을 확인할 수 있다.
 |
| 훈련 종료 부분 |
훈련이 종료될 시점에는 약 1.08로
오류률이 고작 0.02밖에 줄어들지 않은 것을 확인할 수 있다.
따라서 가지고 있는 데이터의 분포에 따라
최적의 오류률을 계산하기 위한 비용이 증가할 수도 있다는 것을 알 수 있다.
마치며
이제 뉴럴 네트워크의 전체적인 소스 코드는 사실상 완성되었다.
하지만, 이 코드는 좋은 코드라고 보기는 힘들며
뉴럴 네트워크를 이해하기 위한
하나의 예로서 바라보는 것이 좋을 것이다.
Pytorch라던가 이전 순방향 전파의 결과 값을 확인할 때
잠깐 사용했던 구글의 tensorflow 등의 훌륭한 프레임 워크가 있기 때문이다.
지금까지는 함수 하나하나를 호출해서
레이어를 구성하는 등의 호출 했지만,
여기서 좀 더 나아간다면 모듈화를 통해
클래스로 호출하는 것이 더욱 적절할 것 이다.
다음에는 새로운 클래스를 하나 구현해
이 곳을 통해 레이어의 추가 하고,
순전파를 비롯해 역전파를 통한 뉴럴 네트워크 훈련 할 필요가 있을 것이다.